Real-World Benefits of RAG in LLMs for SaaS & Product Teams
- Bhuvan Desai
- December 6, 2024
- 6 Minute Read

Large Language Models (LLMs) are great at processing and generating decisions, but they have some limitations. They often rely on older training data, can sometimes provide incorrect information, and may struggle with highly specific or current topics. This is where Retrieval-Augmented Generation (RAG) comes in.
RAG helps LLMs give better answers by using additional, up-to-date information. In this article, we’ll explain how it works and show a real example of how RAG can help someone decide if a company is good to work for.
What is RAG?
RAG stands for Retrieval-Augmented Generation. It’s a method that combines the knowledge already built into an LLM with specific, current data from outside sources. This improves the accuracy and relevance of the responses.
There are tons of examples to be showcased how RAG can help get the best out of LLMs. We will be sharing one of those in this content.
For people who do not know what RAG is, let’s understand this first.
RAG stands for Retrieval Augmented Generation. It is a technique that inputs an LLM with a knowledge that you or your company carries to generate more accurate and current responses.
What are the key benefits of using RAG over directly using LLMs
Key benefits:
Accuracy & Reliability
- Reduces hallucination by grounding responses in real data (we will see where using only LLM can hallucinate)
- Provides verifiable sources for claims (you are the source of information to make validated decisions)
- More current information vs LLM’s training cutoff (informations are retrieved or decisions are made on basis of more current information
Cost Efficiency
- Smaller context window needed (as you are now generating additional and current information while querying)
- Can use smaller, cheaper models effectively (host your own LLMs)
- Reduced token usage for common queries
Knowledge Control
- Update knowledge without retraining (Control information you share)
- Add/remove information instantly
- Domain-specific expertise (use LLMs for your own purpose, for more accurate outcome)
Compliance & Transparency (full control on information your share)
- Traceable information sources
- Auditable response generation
- Better control over sensitive data
Performance
- More relevant responses for domain-specific queries
- Better handling of rare/specific topics
- Improved consistency in answers
Where RAG Can Be Used
- Customer Support: Answer queries using company-specific information.
- Research Help: Summarize data from various sources.
- Content Creation: Generate text with references and sources.
- Chatbots: Provide detailed, real-time answers for customers.
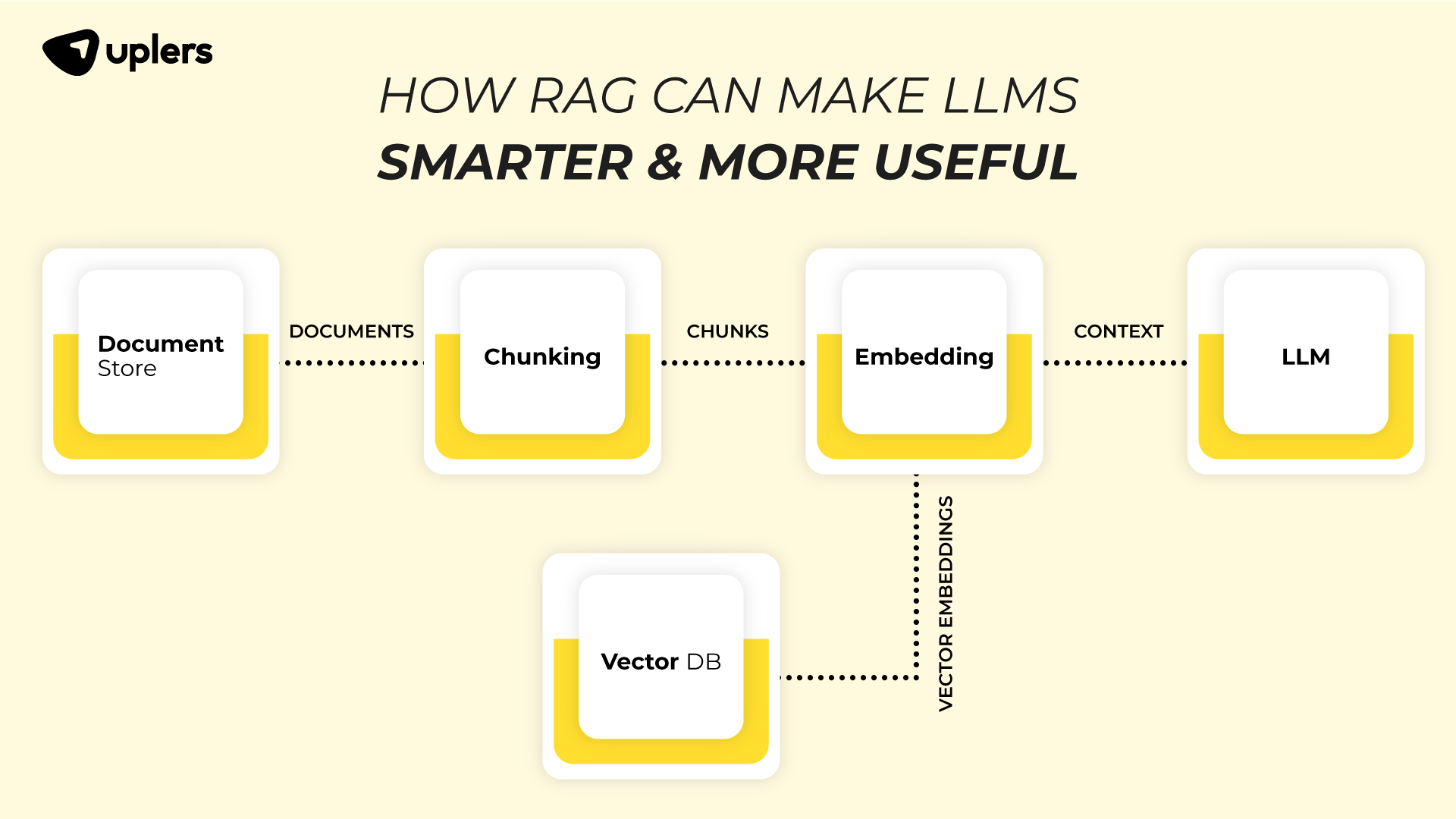
How Does RAG Work?
RAG works in 3 main steps:
Storage:
-
-
- Break down documents into smaller chunks.
- Convert the chunks into a searchable format (embeddings).
- Store them in a vector database for easy retrieval.
-
Retrieval:
-
-
- When a user asks a question, the query is converted into a searchable format.
- Relevant chunks of information are pulled from the database.
-
Generation:
-
- The LLM combines the retrieved data with the user’s question.
- The response is generated using both the external data and the LLM’s own knowledge.
A Real-Life Example: Evaluating a Company for Job Seekers
Traditionally, job seekers rely on:
- Company websites or LinkedIn profiles, which may highlight only positive aspects.
- Glassdoor or similar platforms, which offer limited reviews.
- Recommendations from friends or colleagues, which depend on a small network.
How RAG with LLMs can help you get more accurate and unbiased answer
It will gather the latest information about the company from multiple sources and not just few that a candidate might look at:
- Employee reviews
- News articles
- Financial health
- Social media
- Salary data
It will then analyze Important Factors:
- Work-life balance
- Growth opportunities
- Pay competitiveness
- Company stability
- Employee happiness
Finally it gives:
- Overall company score
- Key strengths and weaknesses
- Specific red flags
- Questions to ask in interviews
- Negotiation tips
Techniques for Using RAG
There are 3 different techniques to implement RAG to train LLM in the above case:
- Basic RAG: Simple website scraping and evaluation
- Multi-source RAG: Combines multiple data sources (website, reviews, news) with structured data (employee count, benefits)
- Chain-of-Thought RAG: Breaks analysis into specific aspects (work-life balance, compensation, growth) and synthesizes findings
Lets deep dive into these 3 techniques with code and outcome. You can use any techniques after experimenting with your data and LLMs you are using, as normally chain-of-thoughts helps you give answers specific to questions you are asking while multisource with structured data helps you grab information into much usable format. You may combine techniques too to get optimum results.
Lets connect OpenAi or any LLM with your API and for example take Mavlers as an example of a company you are researching for.
| # User when inputs in LLMs using API
“Is Mavlers a good company to work for?” # He will get following answer: “Mavlers is a digital services company providing web development, email marketing, and digital marketing solutions. They have good work culture and offer remote opportunities” |
- Now lets use basic RAG technique and see how RAG will change this output
| from typing import List, Dict
from langchain.embeddings import OpenAIEmbeddings from langchain.vectorstores import FAISS from langchain.chat_models import ChatOpenAI import requests from bs4 import BeautifulSoup # 1. Basic RAG class BasicCompanyRAG: def __init__(self): self.embeddings = OpenAIEmbeddings() self.vector_store = FAISS.from_texts([], self.embeddings) self.llm = ChatOpenAI() def evaluate_company(self, company_name: str) -> str: # Scrape basic company info company_data = self.scrape_company_website(company_name) # Store in vector database self.vector_store.add_texts([company_data]) # Query and generate response context = self.vector_store.similarity_search( f”Is {company_name} a good company to work for?”, k=3 ) return self.llm.predict(f”””Based on this context, evaluate {company_name} as an employer: Context: {context}“””) # Example usage def evaluate_company_all(company_name: str): basic_rag = BasicCompanyRAG() basic_result = basic_rag.evaluate_company(company_name) return { ‘basic_analysis’: basic_result } # Usage example if __name__ == “__main__”: company_name = “Mavlers” results = evaluate_company_all(company_name) print(results[‘basic_analysis’]) # Basic evaluation |
| Output – Basic RAG
“Basic RAG Analysis: Mavlers is a remote-first digital services company with 500+ employees. Growing presence in US/UK markets. Focuses on web development and digital marketing solutions.” |
Brings 500+ employees and global presence of US/UK markets giving more specific answers compared to earlier.
- Lets try with Multisources + Structured Data RAG technique
| from typing import List, Dict
from langchain.embeddings import OpenAIEmbeddings from langchain.vectorstores import FAISS from langchain.chat_models import ChatOpenAI import requests from bs4 import BeautifulSoup # 2. Multi-source RAG + Structured Data class MultiSourceCompanyRAG: def __init__(self): self.embeddings = OpenAIEmbeddings() self.vector_store = FAISS.from_texts([], self.embeddings) self.llm = ChatOpenAI() self.structured_data = {} def collect_data(self, company_name: str): sources = { ‘website’: self.scrape_company_website(company_name), ‘reviews’: self.get_employee_reviews(company_name), ‘news’: self.get_news_articles(company_name), ‘linkedin’: self.get_linkedin_data(company_name) } # Store unstructured text for source, text in sources.items(): self.vector_store.add_texts([text], metadatas=[{‘source’: source}]) # Extract structured data self.structured_data = { ’employee_count’: self.extract_employee_count(sources), ‘benefits’: self.extract_benefits(sources), ‘tech_stack’: self.extract_tech_stack(sources), ‘growth_rate’: self.calculate_growth_rate(sources) } def evaluate_company(self, company_name: str) -> Dict: # Get relevant context context = self.vector_store.similarity_search( f”What’s it like to work at {company_name}?”, k=5 ) # Combine with structured data analysis = self.llm.predict(f””” Evaluate {company_name} based on this information: Context: {context} Structured Data: {self.structured_data} “””)
return { ‘analysis’: analysis, ‘structured_data’: self.structured_data, ‘sources’: [doc.metadata[‘source’] for doc in context] } # Example usage def evaluate_company_all(company_name: str): multi_rag = MultiSourceCompanyRAG() multi_rag.collect_data(company_name) multi_result = multi_rag.evaluate_company(company_name) return { ‘multi_source_analysis’: multi_result } # Usage example if __name__ == “__main__”: company_name = “Mavlers” results = evaluate_company_all(company_name) print(results[‘multi_source_analysis’]) # Detailed multi-source analysis |
| Output – Multisource RAG + Structured Data
# Multi-source analysis output: { ‘analysis’: ‘Growing digital services company with strong remote culture and diverse client portfolio’, ‘structured_data’: { ’employee_count’: ‘500+’, ‘tech_stack’: [‘WordPress’, ‘PHP’, ‘React’, ‘HubSpot’], ‘benefits’: [‘Remote work’, ‘Healthcare’, ‘Learning allowance’], ‘growth_rate’: ‘40% YoY’ }, ‘sources’: [‘company_website’, ‘glassdoor’, ‘linkedin’, ‘news_articles’] } |
It breaks output into more structured outcomes, which can be used for different purposes as well. It can also get information like growth as well as benefits if it’s publicly available.
- Lets try with Chain-of-thoughts RAG Technique:
| from typing import List, Dict
from langchain.embeddings import OpenAIEmbeddings from langchain.vectorstores import FAISS from langchain.chat_models import ChatOpenAI import requests from bs4 import BeautifulSoup # 3. Chain-of-Thought RAG class ChainOfThoughtCompanyRAG: def __init__(self): self.embeddings = OpenAIEmbeddings() self.vector_store = FAISS.from_texts([], self.embeddings) self.llm = ChatOpenAI() def evaluate_company(self, company_name: str) -> Dict: # Define evaluation aspects aspects = [ “What’s the company’s work-life balance?”, “How’s the compensation and benefits?”, “What are the growth opportunities?”, “How stable is the company?”, “What’s the company culture like?” ]
evidence = {} for aspect in aspects: # Get relevant context for each aspect context = self.vector_store.similarity_search(aspect, k=3) # Analyze each aspect separately evidence[aspect] = self.llm.predict(f””” Based on this context, answer: {aspect} Context: {context} “””)
# Synthesize final analysis final_analysis = self.llm.predict(f””” Given these findings about {company_name}, provide a final evaluation: Evidence: {evidence} “””)
return { ‘overall_analysis’: final_analysis, ‘aspect_analysis’: evidence } # Example usage def evaluate_company_all(company_name: str): cot_rag = ChainOfThoughtCompanyRAG() cot_result = cot_rag.evaluate_company(company_name) return { ‘chain_of_thought_analysis’: cot_result } # Usage example if __name__ == “__main__”: company_name = “Mavlers” results = evaluate_company_all(company_name) print(results[‘chain_of_thought_analysis’]) # Aspect-by-aspect analysis |
| Output – Chain-of-Thoughts RAG
# Chain-of-thought analysis output: { ‘overall_analysis’: ‘Stable remote employer with good growth trajectory in digital services’, ‘aspect_analysis’: { ‘work_life_balance’: ‘Flexible remote work, project deadlines can impact balance’, ‘compensation’: ‘Market competitive, varies by location and role’, ‘growth_opportunities’: ‘Good exposure to technologies and clients’, ‘stability’: ‘Growing revenue, expanding client base’, ‘culture’: ‘Remote-first, delivery-focused environment’ } } |
Here it brought answers for specific aspects we broke into and asked and gave more to the point answers to the questions usually candidates would have.
The entire example is to learn how RAG can be used with LLM to improvise results of outcome. The above results too have scope of improvisation and can be enhanced to great value depending on what outcome you wish to achieve.
Why RAG is a Game-Changer
RAG makes LLMs more powerful by filling in their gaps. Whether you’re a job seeker evaluating a company or a business creating a smarter chatbot, RAG ensures answers are accurate, reliable, and relevant to your specific needs. By using techniques like Basic RAG, Multi-Source RAG, or Chain-of-Thought RAG, you can unlock smarter and more effective AI solutions.
The best part? RAG is flexible. You can experiment with different methods or combine them to achieve the results you need.
Let’s make smarter decisions with smarter AI!